Aceleración de HPC y Computación Científica
AUTOR: Valeria Arias, Digital Marketing Strategist at MR SOLUTIONS
La aceleración es el camino a seguir para científicos y para la informática de alto rendimiento, de acuerdo a esto, la informática acelerada tiene cuatro pilares:
- El primero es el acelerador (GPU avanzadas).
- La pila de aceleración de cada uno de los cálculos computacionales.
- El tercero son los sistemas.
- El último son los desarrolladores, es decir, las aplicaciones.
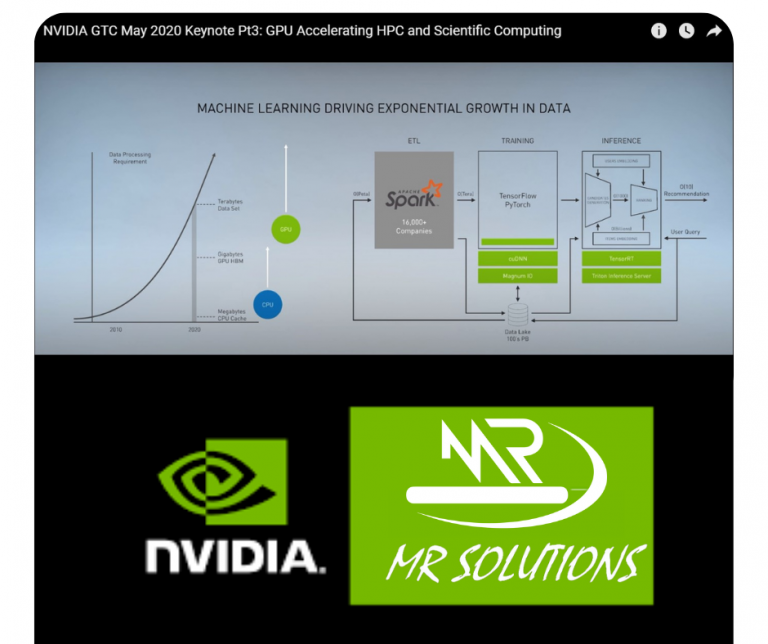
Los avances del Machine Learning y la popularidad de este enfoque ha causado que empresas, instituciones y centros de datos recopilen una enorme cantidad de datos, hablando sobre este proceso de aprendizaje en general, es importante mencionar que consta de tres cosas fundamentales:
ETL que crea el marco de datos, hace toda la ingeniería necesaria para que el algoritmo de aprendizaje automático se entrene. Esto crea un modelo que inicia operaciones que llamamos Inferencia. Estas tres etapas de la tubería tienen desafíos computacionales únicos y diferentes.
La primer etapa de la tubería de aprendizaje automático, procesamiento de datos se está volviendo más complejo. De hecho, es importante recalcar que la mayoría de los científicos de datos gastan la mayoría de su tiempo haciendo ingeniería de características y procesamiento de datos en la etapa delantera de la tubería de aprendizaje automático. Lo que antes solía estar procesando cientos de megabytes a gigabytes y terabytes de datos, ahora las empresas lo procesan rutinariamente con cientos de datos de terabytes y pasan a petabytes de datos.
¿A qué vamos con esto?
Existe una solución de NVIDIA que divide un conjunto de datos muy grande para procesar en pequeños trozos que luego se distribuyen a través de un montón de servidores en un centro de datos programado hasta su finalización. Mientras que la cantidad de datos que están procesando está creciendo exponencialmente.
La CPU en la que se distribuye tiene un conjunto de trabajo fundamental en el orden de megabyte. A una CPU le gusta naturalmente para trabajar su caché y generalmente se almacena en caché en las decenas de megabytes. Cuando el conjunto de datos es ahora los cientos de terabytes y petabytes, la sobrecarga de coordinar los servidores de la CPU se convierten en el mayor cuello de botella y se notan ahora los límites. ¿Qué pasa si en vez de trabajar los procesadores que tiene decenas de megabytes de conjunto de trabajo, avanzamos ahora a un procesador que tiene decenas de gigabytes de conjunto de trabajo y utilizamos múltiples GPU’s para crear recuerdos grandes? Es posible escalar aún más allá de ello.
¿Más información?
Te invitamos a ver el siguiente video:



